周学习总结(4月6日-12日)
周学习总结(4月6日-12日)
一、拓扑数据分析:持续同调
我对拓扑数据分析的步骤理解为:
- 对原始数据进行数据处理,去除噪声、填补缺失值,并进行归一化处理,确保数据质量,生成点云。
- 持续同调:通过 Vietoris-Rips(VR)复形 或 Cech复形,逐步增加半径参数ε,生成嵌套的单纯复形序列,捕捉不同尺度下的拓扑特征,并计算同调群。
- 生成持续图,提取拓扑特征。
Morse函数
在光滑的m-maniflod上的光滑函数,为的非退化点,在$ pU (p) pm$维坐标系,使得:
负号个数即为非退化临界点的index。从而Morse函数为满足一下条件的光滑函数:
- 所有临界点非退化
- 所有临界点都不同
它通过一个光滑函数的临界点(即梯度为零的点:最大值、最小值点)来揭示形状的拓扑结构 。
示例图如下:
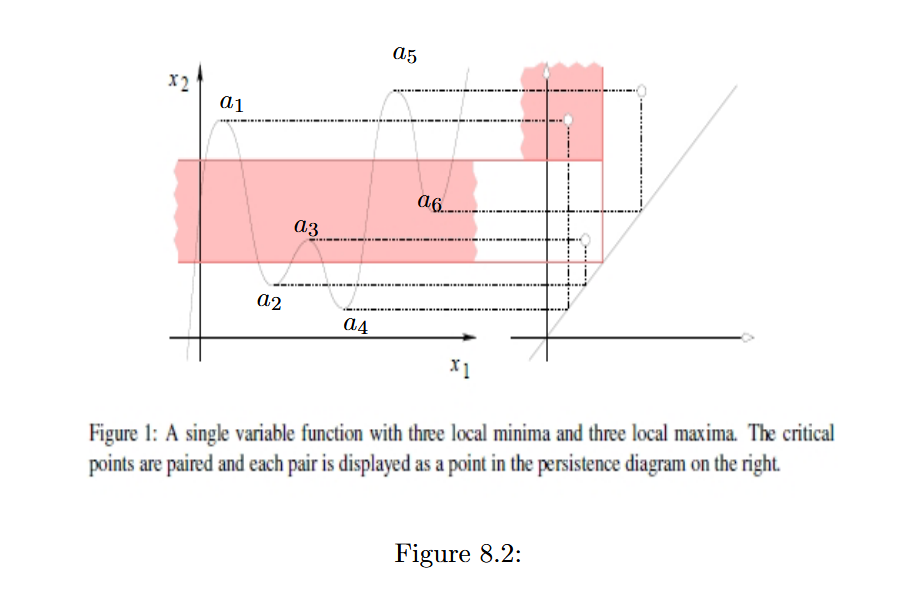
图中,从轴持续上升,从越过和,、结合成对,且,被消灭拉直,以此为例,剩余组合为、和、,Morse函数对应画出持续图,将组合以为轴,以为轴,画点得到持续图。
二、C++
本周主要学习的是内容是:日期问题。
核心是使用Nextday函数:
1 | |
NextDay 函数的作用是将输入的日期(年、月、日)推进到下一天,同时处理闰年、月份切换和年份切换。
其余的根据题目要求,进行对nextday函数进行循环调用,将日期逐日推进,最后打印结果即可。
三、概率论
本周学习的是从贝叶斯定律到概率质量函数和概率密度函数。
- 贝叶斯定律
贝叶斯定律是描述条件概率关系的公式。它的基本公式是:
其中,如果存在个分区,可以明确的以总概率形式写出:
其中:
- 是在已知事件B发生的情况下,事件A发生的概率(后验概率)。
- 是在事件A发生的情况下,事件B发生的概率(似然性)。
- 是事件A发生的先验概率,即在没有任何条件下对事件A发生的估计。
- 是事件B发生的总概率。
举个例子:假设你有一个学校考试的成绩(B),你知道大部分学生通过考试的概率是80%()。但是,如果一个学生非常努力学习(事件A),那他通过考试的概率可能是90%()。贝叶斯定律告诉你,如果你知道某个学生努力学习的概率(),那么你可以更准确地判断他在通过了这次考试情况下,有努力学习的概率()。通过贝叶斯定律,我们可以计算出在通过考试的学生中,有多少人是努力学习的。
- 概率质量函数(PMF)和概率密度函数(PDF)
概率质量函数是用来描述离散型随机变量(也就是那些可能取有限个或可数个数值的随机变量),它给出了每个特定结果发生的概率。
概率密度函数是用来描述连续型随机变量(可以取无数个数值的变量),它描述了某个区间内的概率,通过计算区域下的面积来得出概率。
简而言之:概率质量函数是用来回答独立结果发生的概率,结果与结果之间是离散、无关的。概率密度函数是计算某一个范围内的结果出现的可能性,例如:温度不是只有几个固定的数字,而是可能是任何一个数字,比如 20°C、20.1°C、20.5°C,甚至是 19.99999°C。计算温度在 20°C 到 21°C 之间的概率,就可以通过计算这个范围内的面积来得到。