集成学习
集成学习
一、定义
集成学习是一种通过构建并结合多个弱学习器(基础模型)来提升机器学习性能的机器学习技术。其核心思想是 “三个臭皮匠,赛过诸葛亮”,即通过合理组合多个性能较弱的模型,形成一个性能更优的强学习器,从而提高模型的泛化能力、鲁棒性和预测准确性。
二、基本原理
- 构建多个弱学习器
弱学习器通常是简单模型(如决策树、逻辑回归等),单个模型的性能有限,但在集成后可通过互补性提升整体效果。 - 结合弱学习器的预测结果
通过特定的结合策略(如投票法、平均法、堆叠法等),将多个弱学习器的输出进行整合,得到最终预测结果。
三、核心思想与优势
思想:利用模型的多样性(不同的训练数据、算法参数、特征子集等),降低单一模型的偏差或方差,从而提升整体性能。
优势:
- 提升预测精度:减少过拟合风险,降低方差或偏差。
- 增强鲁棒性:对噪声和异常数据更具容忍性。
- 适用范围广:可用于分类、回归、聚类等多种任务。
四、主要分类及典型方法
根据弱学习器之间的依赖关系,集成学习可分为以下三类:
(一)并行式集成(Bagging)
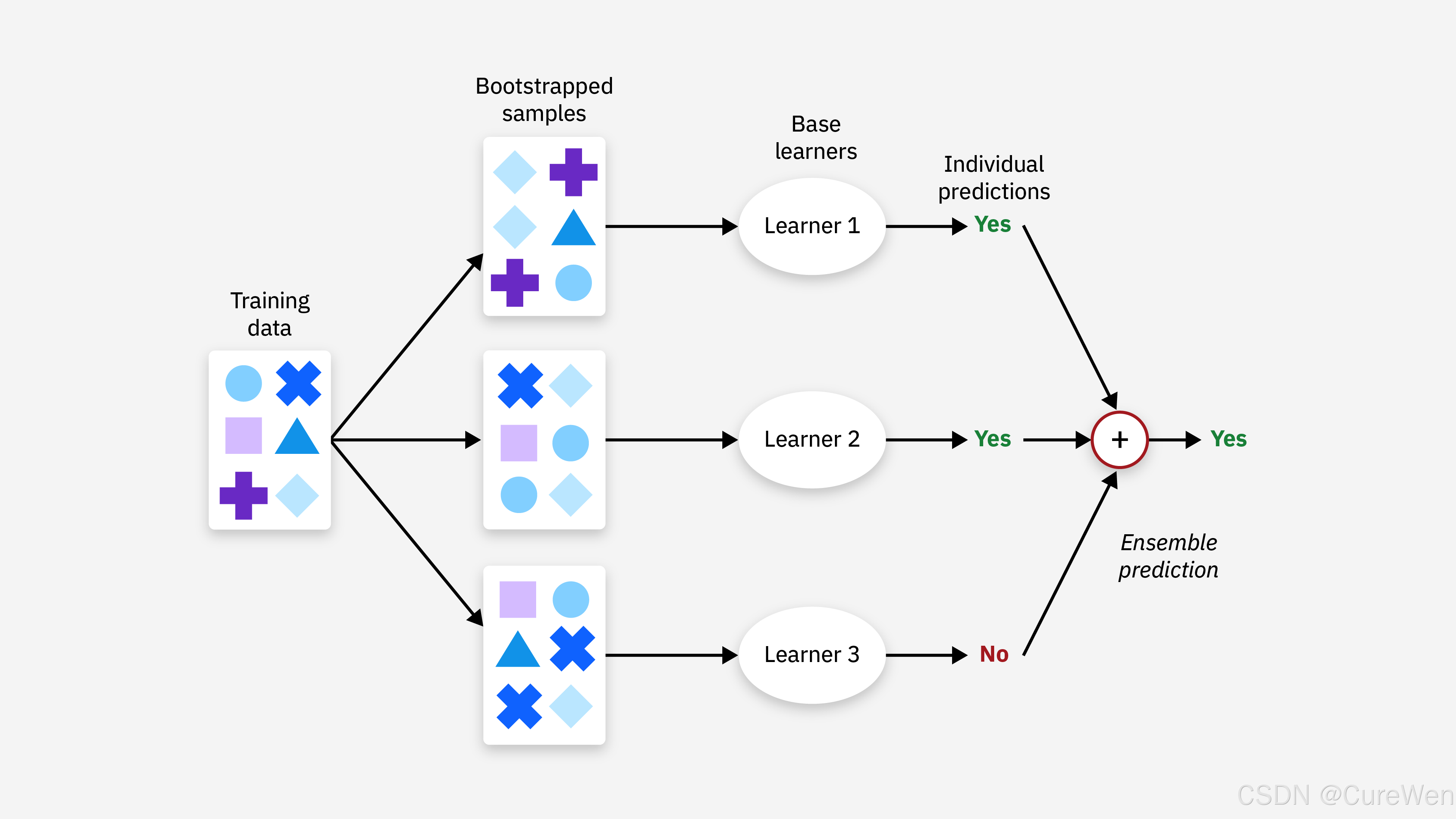
- 特点:弱学习器之间无依赖关系,可并行训练。
- 原理:通过自助采样(Bootstrap)生成多个不同的训练子集,每个子集训练一个弱学习器,最终通过投票或平均法整合结果。
- 代表模型:随机森林(Random Forest),通过随机选择特征子集和样本子集,进一步增强模型多样性。
(二)串行式集成(Boosting)
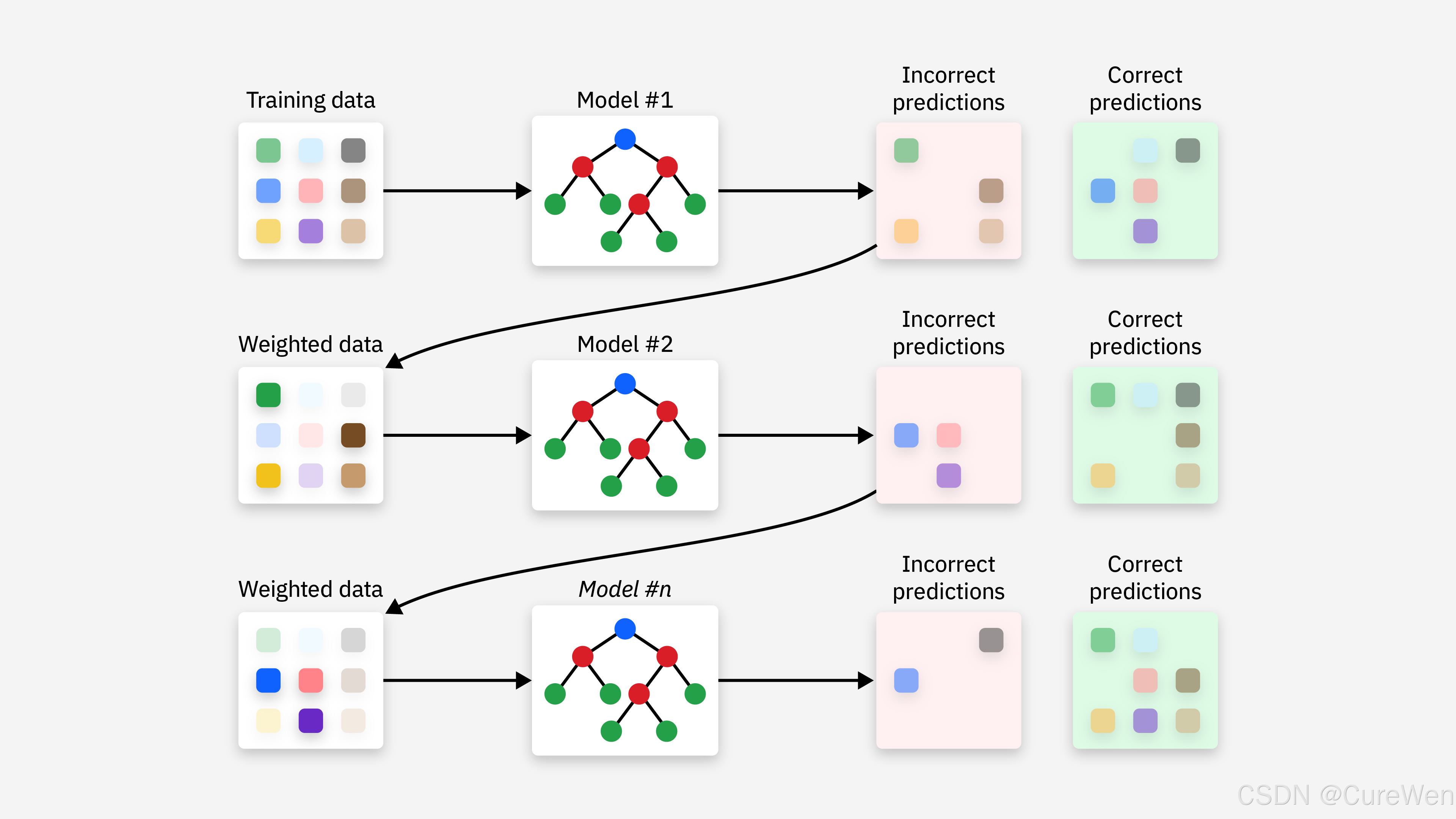
-
特点:弱学习器按顺序训练,每个新模型基于前序模型的错误进行优化。
-
典型方法:
-
AdaBoost(Adaptive Boosting)
- 原理:迭代训练弱学习器,逐步增加前序模型误分类样本的权重,降低正确分类样本的权重,最终通过加权投票整合结果。
-
Gradient Boosting(梯度提升)
- 原理:将损失函数的负梯度作为残差的近似值,迭代训练弱学习器来拟合残差,代表模型包括 GBDT(Gradient Boosting Decision Tree)和 XGBoost、LightGBM 等高效实现。
-
XGBoost
- 原理:XGBoost(eXtreme Gradient Boosting)是梯度提升树(Gradient Boosting Decision Tree, GBDT)的高效实现,属于集成学习中的 Boosting 类算法。其通过串行训练多棵决策树,逐步拟合前序模型的残差(或负梯度),最终将所有树的预测结果累加得到最终输出。
-
(三)堆叠(Stacking)
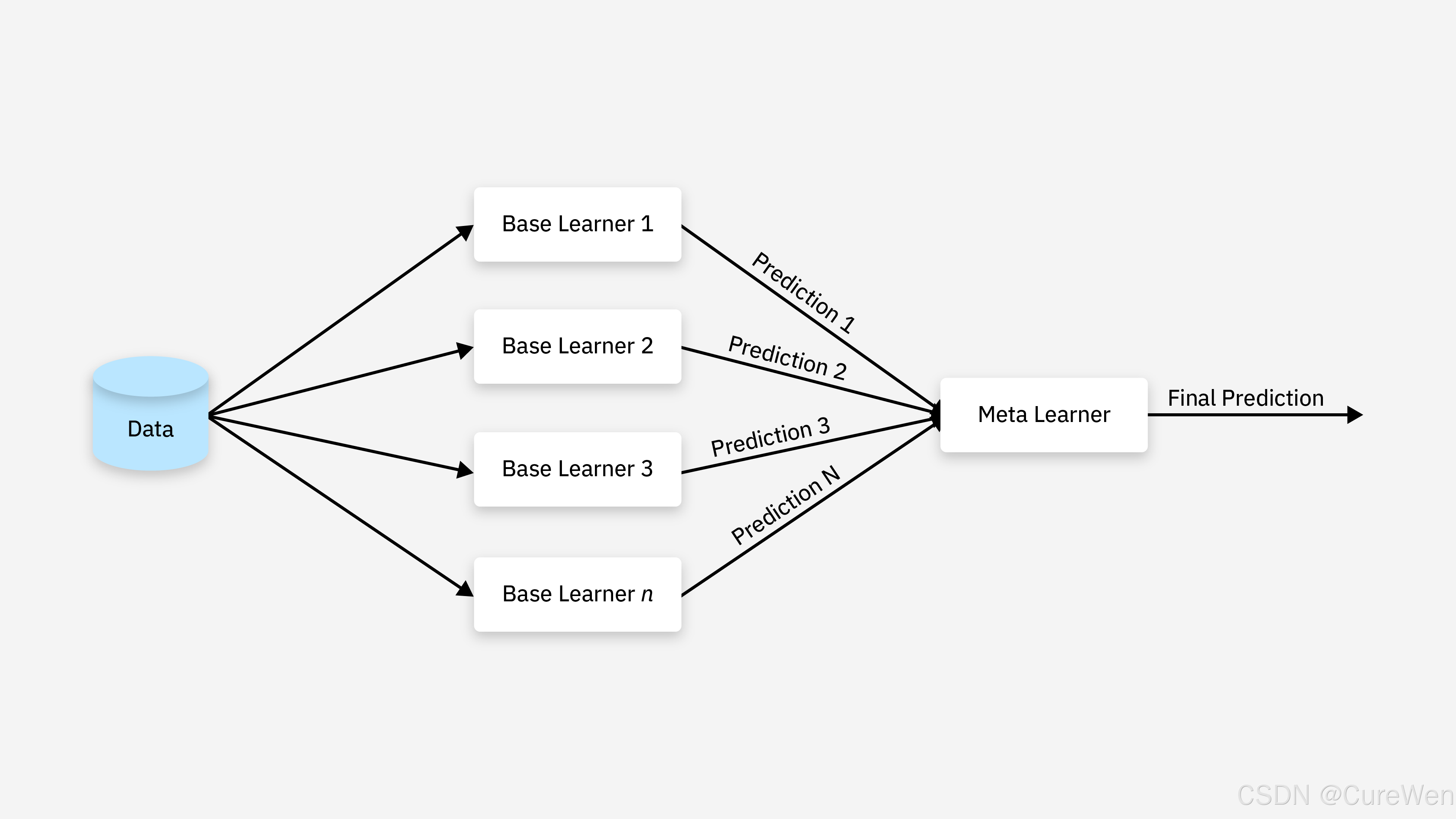
1)Stacking工作机制:
首先先训练多个不同的模型;
然后把之前训练的各个模型的输出为输入来训练一个模型,以得到一个最终的输出。
2)Stacking 训练一个模型用于组合(combine)其他各个基模型。
具体方法是把数据分成两部分,用其中一部分训练几个基模型A1,A2,A3,用另一部分数据测试这几个基模型,把A1,A2,A3的输出作为输入,训练组合模型B。
注意,它不是把模型的结果组织起来,而把模型组织起来。理论上,Stacking可以组织任何模型,实际中常使用单层logistic回归作为模型。这些模型通过综合这些信息以做出最终的决策。
五、结合策略
-
分类任务
- 简单投票法:少数服从多数(硬投票)或加权投票(软投票)。
- 堆叠法(Stacking) :使用元模型(如逻辑回归)整合多个弱学习器的输出。
-
回归任务
- 简单平均法:直接求多个弱学习器预测值的算术平均或加权平均。
六、关键问题
-
多样性(Diversity)
- 弱学习器之间需具有一定差异,否则集成效果有限。可通过不同的训练数据、算法、参数或特征采样实现。
-
偏差 - 方差权衡
- Bagging 类方法主要降低方差(如随机森林),Boosting 类方法主要降低偏差(如 GBDT)。
-
计算成本
- 并行式方法(如 Bagging)可通过并行计算提升效率,串行式方法(如 Boosting)需顺序训练,计算成本较高。
集成学习
https://github.com/DukeZhu513/dukezhu513.github.io.git/post/integrated-learning-1jh0n7.html