Quantization-Aware Training(QAT)综述笔记
Quantization-Aware Training(QAT)综述笔记
本文的构思与内容主要基于以下综述:
Jiaqi Zhang. Survey of Quantization-Aware Training (QAT) Applications in Deep Learning Quantization . AICSS 2025, September 19–21, 2025, Beijing, China. DOI:10.1145/3776759.3776826
随着人工智能模型规模的指数级增长,计算效率与资源约束之间的矛盾日益尖锐。量化感知训练(Quantization-Aware Training, QAT)作为模型压缩的核心技术,自2018年由Jacob等人提出以来,已成为在有限硬件资源下部署大规模模型的主流范式。尤其在2024-2025年间,QAT被广泛应用于大语言模型(LLMs)、扩散模型(DiTs)等前沿架构,其性能优势与部署潜力备受关注。
然而,这一领域的研究正面临碎片化挑战:尽管大量改进方法(如梯度近似优化、低秩更新、混合QAT-PTQ框架)不断涌现,却缺乏系统性梳理与横向对比。现有综述多聚焦于基础概念或与后训练量化(PTQ)的简单比较,未能覆盖近年来在生成模型、神经形态硬件、超低比特压缩等方向上的突破性进展。
为此,本文旨在提供一个结构化的知识框架,全面回顾QAT从历史发展到当前应用的演进脉络,并深入剖析其在低比特场景下的核心瓶颈(如梯度传播不稳、激活敏感性、数据依赖性强)及对应的前沿解决方案。
一、QAT的历史背景与技术演进
1.1 人工智能与计算效率的悖论
自1950年图灵提出"机器能否思考"的命题以来,人工智能已走过70余年发展历程。从1958年的感知机到2012年AlexNet的突破,神经网络的规模和复杂度呈指数级增长。然而,这带来了严峻挑战:模型规模扩大与计算资源有限之间的矛盾日益突出。2014年,Geng和Luo观察到先进CNN虽提高了图像识别精度,但推理时间显著延长;Canziani等人进一步指出,精度提升伴随着推理时间和能耗的大幅增加。
1.2 模型压缩技术的兴起
2015-2016年间,模型压缩技术应运而生,主要包括三类方法:
- 剪枝:Han等人证明深度神经网络包含大量冗余权重
- 量化:Courbariaux等人首次引入二值权重训练,Rastegari等人扩展至二值卷积
- 知识蒸馏:Hinton等人提出让大"教师"模型指导小"学生"模型训练
Kuzmin等人通过理论和实证研究表明,与其他方法相比,量化引起的误差和性能下降通常更小、更稳定,这奠定了量化技术在模型压缩中的核心地位。
1.3 QAT的诞生与发展
2018年,Jacob等人正式提出量化感知训练(QAT) ,解决了后训练量化(PTQ)在低比特场景下精度急剧下降的问题。QAT的核心思想是将量化过程纳入训练阶段,使模型学会适应并补偿量化误差。此后,QAT迅速成为主流量化方法,并集成到TensorFlow Lite和PyTorch等框架中。
2022-2024年间,QAT在大语言模型、Transformer架构、嵌入式系统和医疗图像分割等领域广泛应用。到2025年,研究者开始系统性总结QAT的局限性并提出创新性改进方法,包括增强梯度估计、结构优化、知识蒸馏、低秩更新策略以及QAT-PTQ混合方案等。
二、QAT方法论:原理、机制与比较
2.1 QAT的核心概念与数学表达
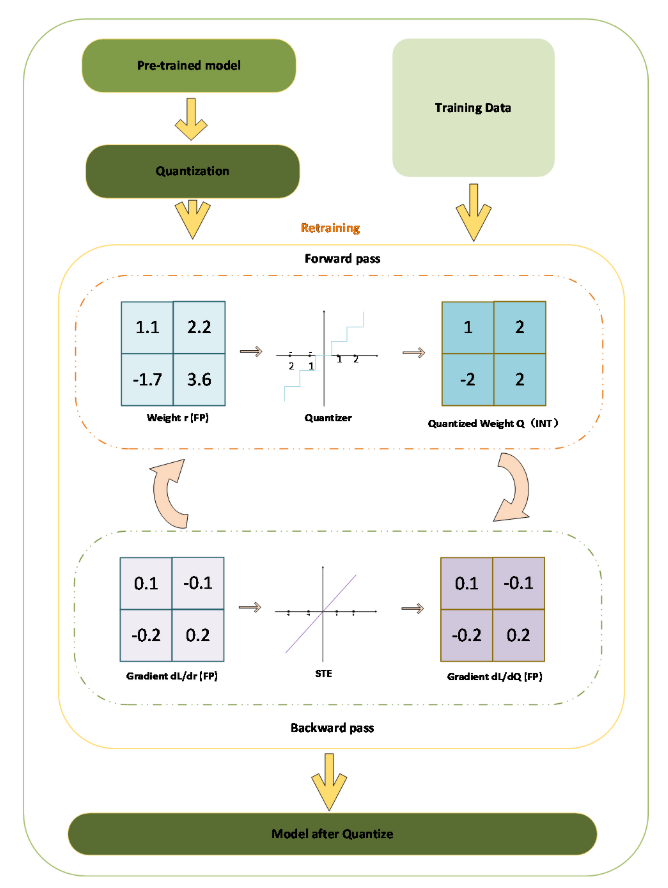
QAT通过在模型中引入伪量化模块(fake quantization module)实现,该模块包含量化和反量化操作。在前向传播过程中,此模块插入到浮点模型将被量化为整数模型的位置,从而模拟整数量化的截断和舍入效应。
量化函数可表示为:
其中,r为输入,s为缩放因子,z为零点。这些参数共同定义了量化下可表示的值范围。超出此范围的值被clipping操作截断,而舍入将浮点结果转换为整数。
反量化函数定义为:
在反向传播过程中,梯度通过直通估计器(Straight-Through Estimator, STE)传播到基础权重:
细节:权重和激活在训练期间以整数形式模拟,但以浮点格式存储,所有前向乘加操作在FP32中执行以支持梯度计算。在推理时,采用整数运算,这可能导致训练与推理之间的数值差异。
2.2 QAT与PTQ的全面对比
后训练量化(PTQ)与量化感知训练(QAT)是两种主要的量化策略,它们在多个维度存在显著差异:

关键实验发现:在8位精度下,PTQ可保持可接受的精度,但在4位以下精度急剧下降;QAT在ResNet和MobileNet等模型上比PTQ更稳定,尤其在低比特设置下;在SMNIST数据集上,PTQ仅达到40%精度,而QAT达到96%;在MobileNetV1-0.25上,QAT将Untracked和Cracked的F1分数提高了0.02-0.2
实践权衡:QAT通常能提供更高的精度,但计算成本显著增加。前向传播可以使用低精度执行,但反向传播需要高精度,使操作数量几乎翻倍。这使QAT在计算上效率低下,不太适合大规模模型。相比之下,PTQ不需要重新训练,可以用少量校准样本应用,计算成本低,但通常会降低精度。
2.3 QAT训练流程详解
QAT的标准训练流程包含以下关键步骤:
- 初始化:加载预训练的浮点模型或从头初始化
- 插入伪量化节点:在需要量化的权重和激活前插入量化-反量化操作
- 前向传播:使用量化操作模拟整数推理
- 损失计算:基于量化输出计算任务损失
- 反向传播:使用STE传播梯度
- 参数更新:更新模型参数和量化参数(如缩放因子)
- 转换:训练完成后,将模型转换为真正的整数推理图
三、QAT的应用领域与前沿进展
3.1 传统CNN网络应用
在TinyML领域,QAT已被证明能有效压缩轻量级CNN,同时保持精度。例如,Zhang等人将QAT应用于轻量级CNN模型进行裂缝检测,在资源受限的设备上,QAT使MobileNetV2×0.5达到0.83的F1分数,几乎与其浮点对应物相匹配。Alhussain和Lin将QAT与知识蒸馏结合用于CNN压缩,引入双教师网络(Dual-Distillation),在CIFAR-10和CIFAR-100数据集上进一步提高了CNN量化性能。
3.2 新一代神经网络架构
状态空间模型(SSMs) :Abreu等人将QAT应用于S5网络的关键组件,包括循环权重、归一化层和激活函数,在MNIST和大多数LRA任务上精度下降不到1%。Siegel等人进一步将QAT应用于SSMs,将计算复杂度降低了两个数量级,并成功部署在AIMC芯片上。
脉冲神经网络(SNNs) :最近研究证明,通过优化梯度传播和SQUAT框架,QAT使SNN能在2-4位精度下部署,显著提高了在神经形态芯片和边缘AI设备上部署SNN的可行性。
扩散Transformer(DiTs) :Lu等人将QAT引入大规模DiT模型,将权重量化为三元值(-1,0,1)。通过架构改进和将AdaLN替换为RMSNorm以提高稳定性,他们实现了接近全精度模型的性能。使用2位CUDA核心,该方法将模型检查点压缩了10倍以上,推理内存消耗减少了约6倍。
3.3 大语言模型(LLMs)量化
部署大语言模型在资源受限设备上面临计算效率低、内存和能耗需求高、延迟不可接受等挑战。QAT已成为压缩LLMs和实现高效推理的关键方法。
- Hasan等人系统评估了10M到1B参数的LLMs,证明QAT可以将模型压缩高达68%。在INT4量化下,计算成本和功耗降低60%,同时保持超过94%的全精度性能。
- BitNet模型中,QAT实现三元量化,在极低比特设置下保持精度,达到8倍吞吐量提升,同时保持98.6%的FP16精度。
- Lee等人结合潜在矩阵分解与多尺度残差补偿,实现亚1位极端量化,实现近31倍内存压缩和5倍推理加速。
- Choi等人引入旋转、裁剪和分区(RCP)策略,在W2A4KV4配置下实现LLMs的激进压缩。应用于LLaMA2-7B时,内存消耗减少5.29倍,WikiText2上仅损失2.84个困惑度点。
3.4 其他软件应用
- 文本到语音(TTS) :Kawamura等人将QAT应用于轻量级TTS模型,将参数量化至1.58位(接近三元精度),模型大小减少83%,同时保持自然语音质量。
- 推荐系统:Zhou等人指出,大规模推荐模型中的嵌入表超过1TB,对训练和推理构成严重瓶颈。通过将QAT引入推荐系统,他们在INT4精度下保持了训练和推理性能,没有精度损失。此外,QAT作为隐式正则化器,减轻了过拟合,减少了训练通信开销和内存消耗。
3.5 硬件部署应用
QAT在各种硬件平台上展现出不同的性能特性:
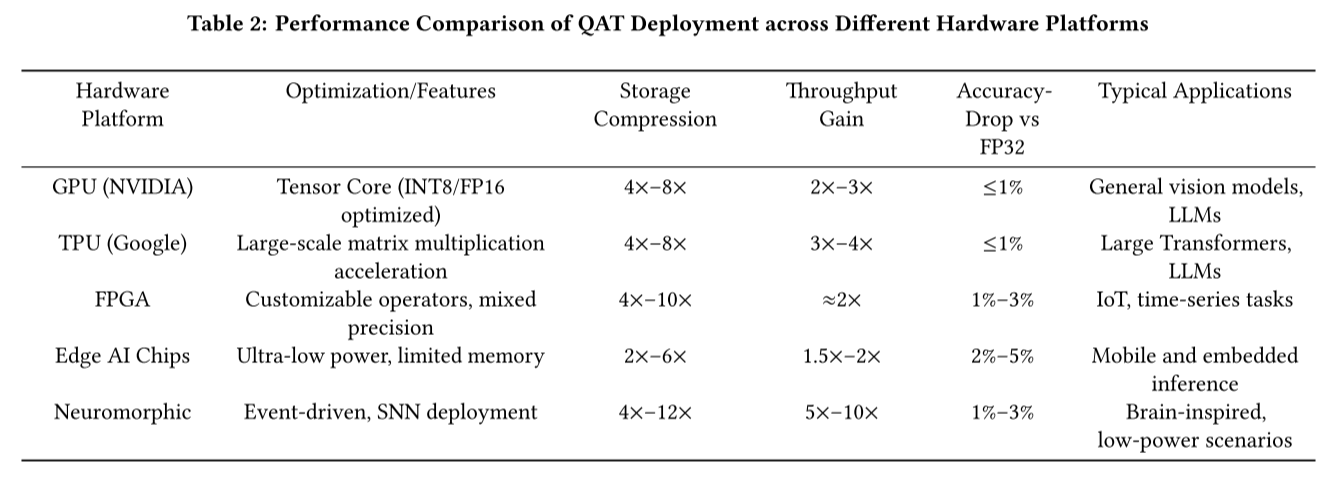
故障和变异性感知QAT:Biswas等人提出一种正则化框架,解决位故障和低比特噪声问题。在CIFAR-10和N-Caltech 101数据集上,他们的4位QAT通过缓解位引起的断续错误和设备电阻变化,实现了强大性能。
神经形态硬件:Arfa等人将QAT应用于部署在SpiNNaker2神经形态芯片上的脉冲神经网络(SNN)进行手势识别。该方法在DVS手势数据集上达到94.13%的精度,在低功耗推理条件下保持接近FP32的性能。
超低功耗语音处理:Itani等人为听觉设备设计了实时语音分离网络。通过使用混合精度量化的QAT,他们在GAP9上部署了该模型,推理时间比FP32基准减少了3.5-4倍。
四、QAT的挑战与创新改进方法
4.1 QAT面临的核心挑战
1. 梯度传播机制存在根本性缺陷。
量化感知训练(QAT)依赖直通估计器(Straight-Through Estimator, STE)处理不可微的量化操作(如 round 和 clip)。然而,STE 本质上是一种启发式近似,缺乏严格的理论支撑。在前向传播中,模型使用真实的量化值进行计算;而在反向传播中,梯度却通过恒等映射(即 ∂Q(x)/∂x ≈ 1)回传,导致前后向过程严重不一致。这种不一致性不仅引入显著的量化误差,还可能使梯度方向偏离真实最优路径,进而引发收敛困难、训练不稳定、精度下降以及不同层之间的梯度不平衡问题。
2. 训练开销与资源消耗过高
QAT 的计算复杂度远高于标准浮点训练。尽管前向传播可采用低精度运算,但反向传播仍需执行两次大规模高精度浮点矩阵乘法以计算权重和激活的梯度,使得整体训练时间几乎翻倍。对于大语言模型等超大规模架构,这导致 GPU 内存占用急剧上升——例如 LLaMA-7B 的 QAT 训练曾需超过 60GB 显存。此外,若采用非均匀量化策略以提升精度,还会引入额外的硬件适配成本;而为防止累加器溢出,需设计更复杂的定点运算单元。更不利的是,当模型需在迭代中微调时,量化流程往往必须从头开始,进一步放大了时间和资源开销。
3. 低比特量化面临严重的累积误差与收敛障碍。
当量化位宽降至 4 位以下时,模型表征能力急剧退化,精度损失显著加剧。实验表明,2 位模型常出现收敛极慢甚至完全发散的现象,而 8 位模型通常能稳定训练,二者之间存在巨大的梯度动态差异。这种不稳定性源于离散化带来的信息瓶颈:有限的量化桶无法充分表达复杂激活分布,导致误差在深层网络中逐层累积。尤为棘手的是,在 W4A4 等低比特配置下,难以定位性能下降的主因——是权重量化还是激活量化主导了误差?这种模糊性阻碍了针对性优化,也限制了 QAT 在极端压缩场景中的实用性。
4. 激活与权重对量化高度敏感,尤其在生成模型中
在扩散模型等生成式架构中,激活值在重训练过程中展现出极大且高度动态的范围。传统的均匀量化假设固定缩放因子,迫使小幅度值被过度压缩、大幅度值被裁剪截断,从而破坏生成质量并延缓收敛。更复杂的是,激活分布在不同训练步长间持续演变,而归一化操作(如 LayerNorm)又会进一步扭曲权重的原始统计特性。在此背景下,简单的裁剪或均匀量化难以有效建模长尾分布和离群值,导致量化误差在关键层(如投影层)集中爆发,甚至引发周期性振荡,使整个训练过程陷入不稳定状态。
5. QAT 对数据规模与训练策略高度依赖。
QAT 的有效性严重受限于训练数据的数量与分布。在小规模数据子集上训练时,中间层的量化误差极易累积,导致性能大幅下降。现有核心集(coreset)选择方法通常忽略量化引入的特异性误差,无法有效指导样本筛选。此外,某些结构组件对量化极为脆弱——例如扩散模型中的时间嵌入层、Transformer 中的 FC2 投影层或目标检测中的关键类别头——这些“敏感层”一旦被粗粒度量化,会引入不成比例的性能损失。即便引入知识蒸馏等辅助手段,也难以完全补偿因数据不足或结构敏感性带来的精度塌陷,这限制了 QAT 在数据稀缺或任务关键场景中的适用性。
4.2 前沿改进方法
随着 QAT 在实际部署中面临的挑战日益凸显,研究者们从多个维度提出创新性解决方案。这些改进可大致分为四类:梯度近似改进、模型结构与训练策略调整、QAT-PTQ 混合策略、以及外部辅助技术。
1. 梯度近似改进:超越 STE 的启发式设计
QAT 的根本瓶颈在于 STE 对不可微量化函数的粗暴近似。近年来,研究者致力于构建更精确、更自适应的梯度传播机制。
-
动态/自适应量化器
Xu 等人提出的 MetaGrad 方法,用超网络替代固定 STE。该超网络接收主网络的梯度作为输入,动态预测最优量化算子,从而生成更贴合当前优化状态的伪梯度。在 ResNet-20 上,其精度几乎与 FP32 无异,显著提升了低比特下的稳定性。Huang 等人则提出 ALRS (Adaptive Learning Rate Scaling) ,为不同比特位宽分配特定学习率,以缩小不同精度下梯度幅度的差异。这一策略有效缓解了 2-bit 训练中常见的梯度失衡问题,使低比特收敛成为可能。
-
公式级修正:减少离散化误差
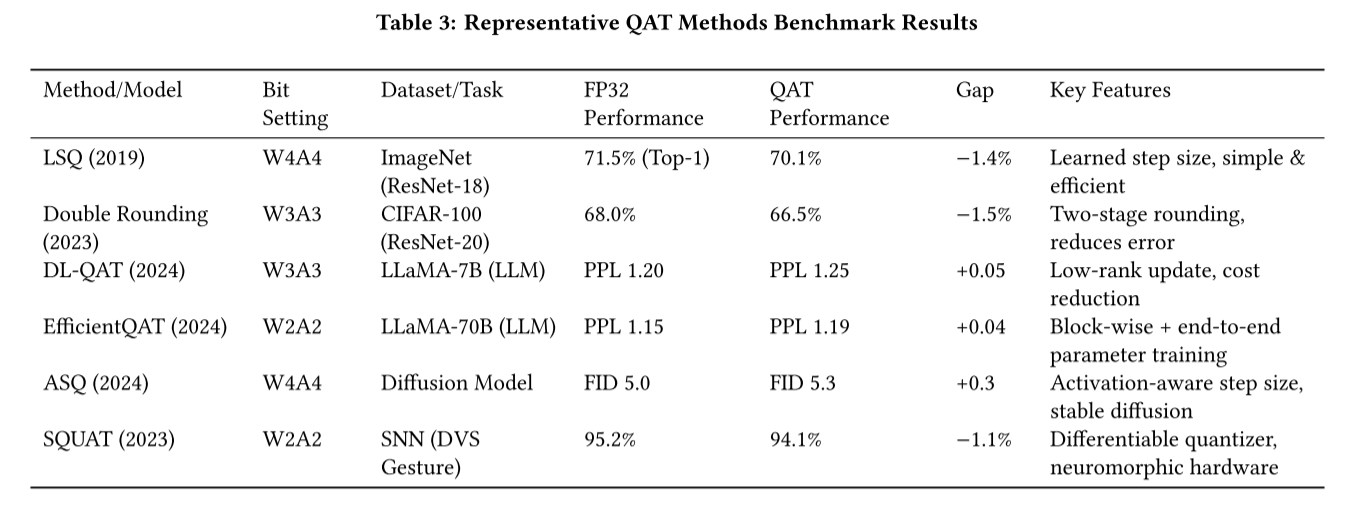
Liu 等人提出的 Weight Dilation 技术,在不改变原始权重分布的前提下,将未饱和通道内的权重“扩张”至量化区间边界,从而压缩激活范围,降低舍入误差。该方法在扩散模型上验证有效,是解决激活动态范围过大的关键手段之一。Huang 等人提出的 Double Rounding 则从量化路径入手:不再直接从 float 转换到低位(如 W3A3),而是先转换到高位(如 W8A8),再降至目标位宽。这种两阶段舍入显著减少了信息损失,在 CIFAR-100 上,其 W3A3 设置下的 Top-1 准确率仅比 FP32 低 1.5% (见 Table 3),优于多数同期方法。
-
量化建模与正则化:理论驱动的稳定化
Ke 等人提出的 DL-QAT 将量化过程分解为两个部分:一是每组参数获得可学习的缩放因子,避免缩放失败;二是仅更新一小部分 LoRA 矩阵,而非全参数。这种方法在 LLaMA-7B 上实现了 仅训练 1% 参数即可超越先前 QAT 方法,并将 GPU 内存消耗从 >60GB 降至 33GB,速度提升 30 倍。Chen 等人进一步推导出 QAT 缩放律(Scaling Law),联合考虑模型规模、数据量和量化粒度,为选择合适的比特宽度提供理论指导。该工作指出,当模型规模与数据量不匹配时,即使采用先进 QAT 方法,精度也会急剧下降——这解释了为何某些大模型在低比特下难以收敛。
2. 模型结构与训练策略调整:效率与精度的平衡
除了改进梯度传播,研究者也从模型架构和训练流程入手,以提升 QAT 的效率与鲁棒性。
-
结构层面的敏感层保护
Chen 等人发现,Transformer 中的 FC2 投影层对量化极度敏感,是导致整体性能下降的主要瓶颈。他们提出一种“混合精度配置”:将 FC2 层保留为 8 位,其余层设为 4 位。此简单调整使量化误差减少 20–43%,并在 ImageNet 和 LLM 任务中均取得显著收益。Liu 等人提出的 Temporal Parallel Quantizer 则针对时序模型(如 SSMs),为每个时间步预设独立的量化参数,实现并行处理,大幅提高训练吞吐量。
-
高效训练框架:降低资源门槛
Ke 等人的 DL-QAT 不仅是结构改进,也是一种高效的训练范式。它通过低秩更新策略,将训练成本降至传统 QAT 的 1/30,使 3-bit LLaMA-7B 的训练在消费级 GPU 上成为可能。Chen 等人提出的 EfficientQAT 更进一步,包含两大核心技术:
- Block-wise All Parameters (Block-AP) :按块分批优化所有参数,扩大解空间,缓解低比特下的精度损失;
- End-to-end Quantization Parameters (E2E-QP) :端到端联合优化所有量化参数,提升整体一致性。
该方法在 LLaMA-2-70B(W2A2) 上实现了突破性成果:在单张 A100-80GB GPU 上仅需 41 小时训练,精度损失 <3% (见 Table 3),这是首次在如此大规模模型上实现 2-bit QAT 的成功案例。
3. QAT-PTQ 混合策略:取长补短的实用主义
纯 QAT 成本高昂,纯 PTQ 精度不足。混合策略应运而生,旨在兼顾效率与精度。
-
两阶段渐进式量化
-
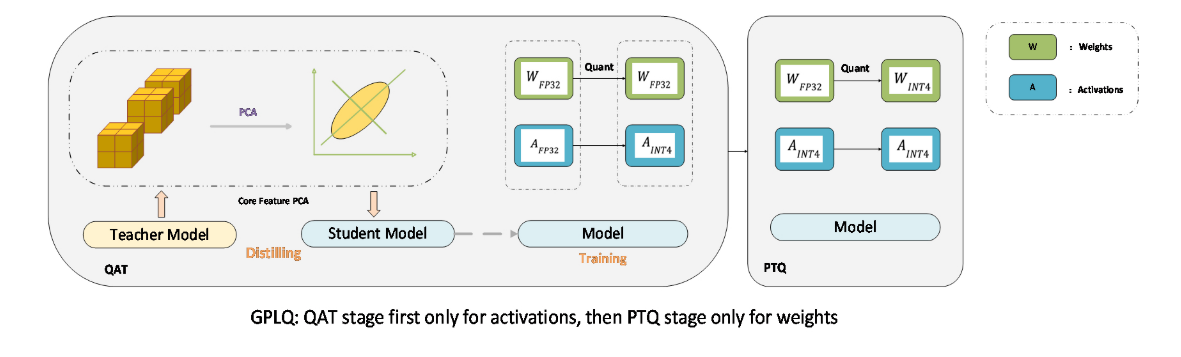
Liang 等人提出的 GPLQ 框架将量化分为两个阶段:- 第一阶段:仅对激活进行 QAT,权重保持 FP32,用一个 epoch 即可稳定激活分布;
- 第二阶段:冻结激活量化参数,对权重应用 PTQ,并辅以 QwT 误差补偿。
该方法 GPU 内存占用低于 FP32,训练时间仅需 1–2 小时,比传统 QAT 快 100 倍以上,同时在 ViT 任务上保持接近 QAT 的精度。
-
客户端自适应混合策略
Zheng 等人提出的 FedHQ 框架应用于联邦学习场景,根据不同客户端的硬件性能和数据分布,动态分配 QAT 或 PTQ 策略:- 精度敏感客户端 → 使用 QAT;
- 速度导向客户端 → 使用 PTQ。
该框架通过机器学习动态调整策略,最终实现 比全 QAT 快 1.5–2.47 倍,精度却接近 QAT 的理想平衡。
4. 外部辅助技术:知识蒸馏与数据驱动优化
为弥补 QAT 自身的局限性,研究者引入外部知识或数据驱动机制,从更高层次引导模型学习。
-
知识蒸馏:利用全精度模型的“教师”信号
Liu 等人提出的 Block-wise Knowledge Distillation,在块级别对齐量化模型与全精度模型,不仅恢复精度,还缩短反向传播路径,降低内存消耗。该方法在 TinyML 任务中效果尤为突出。Li 等人则提出 Time Information Precalculation,预先计算并存储时间嵌入和投影层的输出,避免在推理时量化这些敏感组件,从而显著提升生成质量。
-
数据驱动与中间层校正
Tong 等人提出的 QuaRC 框架,专为小数据集设计。其核心是 RES(Relative Entropy-based Coreset Selection)指标,用于识别最能暴露量化误差的样本,从而实现高效错误校正。在 MobileNetV2 + 2-bit + CIFAR-100 的极端设置下,仅用 1% 数据即提升 9.52% 精度。Yu 等人提出的 BWRF(Block-wise Replacement Framework) 则让全精度模型在训练过程中逐步“替换”低比特模型的部分模块,形成混合精度(MP)指导信号,有效缓解低比特下的表示能力不足和梯度不匹配问题。
基准性能对比:代表性 QAT 方法实证分析
为了直观展示上述改进方法的实际效果,我们引用论文中的 Table 3,汇总了五项代表性工作的性能表现:
五、结论与未来方向
5.1 QAT技术总结
量化感知训练(QAT)作为模型压缩的关键技术,通过在训练过程中模拟量化效果,使模型能够适应并补偿量化误差。自2018年提出以来,QAT已从简单的8位CNN量化发展为支持极端低比特(1-2位)部署的复杂技术体系。它在视觉模型、大语言模型、扩散模型和各类硬件平台上的成功应用,证明了其在AI部署生态中的核心地位。
然而,QAT仍面临梯度传播不准确、计算开销大、低比特不稳定性、激活敏感性和数据依赖性等挑战。最近的研究通过梯度改进、结构优化、混合策略和辅助技术等多种途径应对这些挑战,取得了显著进展。
5.2 未来研究方向
1. 混合精度和自适应量化
结合混合精度训练与自适应步长策略,增强QAT在低比特环境中的稳定性,同时确保计算效率。这需要开发更加智能的位宽分配算法,根据层重要性、激活分布和任务需求动态调整量化粒度。
2. 跨硬件联合优化
开发跨平台优化框架,解决GPU、TPU、FPGA和边缘设备的异构特性,实现统一量化策略和硬件协同设计。这需要建立硬件感知的量化模型,根据目标平台的计算特性、内存层次和能耗约束自动调整量化参数。
3. 类脑计算和新架构
探索QAT在神经形态芯片和存内计算中的应用,突破传统存储墙和能效瓶颈。这需要重新思考量化原理与脉冲神经网络、光计算等新计算范式的结合方式,开发适合这些架构的专用量化方法。
4. 标准化基准和评估系统
建立统一的QAT评估协议和开放基准库,减少不同论文间结果不可比的问题,促进该领域形成更标准化的研究范式。这需要涵盖不同模型架构、任务类型、比特宽度和硬件平台的综合测试套件,以及公平的评估指标和协议。